文字コードの違いでお困りの方へ。
本記事では、「Unicode、UTF-8、Shift-JISの違い」について詳しく解説します。
この記事を読むことで、次のことが理解できるようになります。
- Unicode
- UTF-8
- Shift-JISの基本情報と使い方
- 変換対応表と使えない文字一覧
- 文字化けの原因と解消方法
- それぞれのメリット・デメリット
これらの情報を元に、自分に最適な文字コードを選ぶための知識を身につけましょう。

1. Unicode、UTF-8、Shift-JISの違いと基本情報
Unicode、UTF-8、Shift-JISの違いを理解することは、特にウェブ開発やデータ処理を行う際に非常に重要です。
これらの文字コードは、それぞれ異なる目的や特性を持ち、適切に使い分けることで作業の効率化やエラーの防止につながります。
この章では、それぞれの基本情報と特徴、利用シーンについて詳しく解説します。
1.1. Unicode、UTF-8、Shift-JISとは何か?
まず、Unicode、UTF-8、Shift-JISがそれぞれ何であるかを理解しましょう。
Unicodeは、すべての文字を統一的に扱うための国際文字コード規格です。
全世界の文字を一つの体系で表現することを目指しており、現在ではほとんどのプラットフォームで標準として採用されています。
例えば、アラビア文字、キリル文字、漢字など、幅広い文字を含むため、国際的なプロジェクトに非常に便利です。
UTF-8は、Unicodeの符号化方式の一つです。
可変長のバイト(1~4バイト)を使用して文字を表現し、英数字は1バイト、漢字は3バイトなどのように効率的にデータを格納します。
これにより、ASCIIとの互換性が高く、ウェブページや電子メールなど、広範な用途で利用されています。
UTF-8のもう一つの利点は、データが軽量で、特に英数字のみを使用する場合に効率的に通信できる点です。
例えば、英語圏のウェブサイトであれば、UTF-8の方がデータ転送量が少なく、ページの読み込み速度が向上することがあります。
Shift-JISは、日本語を表現するための文字コードで、特にWindowsや日本のウェブサイトで広く使用されています。
2バイトを使って漢字や仮名を表現するため、日本語特有の文字を効率的に扱うことができます。
しかし、国際的な文字との互換性が低いため、国際プロジェクトにはあまり向いていません。
Shift-JISは日本国内での使用が中心ですが、日本の歴史的な文書や古いアプリケーションとの互換性を保つために重要な役割を果たしています。
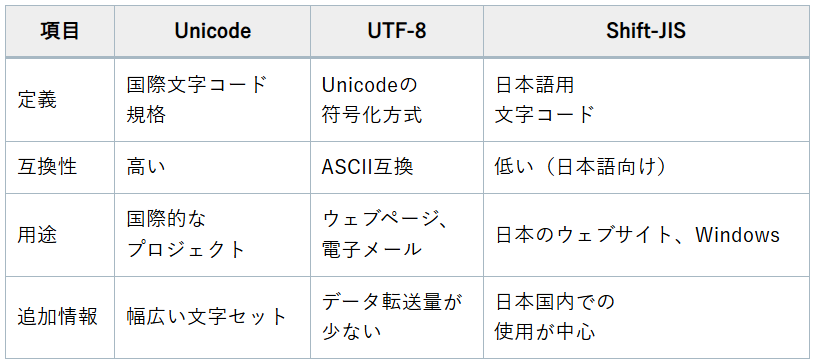
1.2. Shift-JISとUTF-8の変換対応表と使えない文字一覧
Shift-JISとUTF-8の変換は、特に日本語を扱う際に重要なポイントです。
しかし、これには注意が必要で、変換の過程で文字化けが発生することがあります。
Shift-JISとUTF-8の変換対応表を使用することで、どの文字がどのように変換されるかを確認することができます。
例えば、Shift-JISの「0x8140」(全角スペース)は、UTF-8では「0xE38080」となります。
このように、正確な対応表を使用することで、データの正確な変換が可能になります。
特に、文字コードの変換ツールやプログラムを使用する際には、この対応表が不可欠です。
プログラム開発者は、対応表を参照しながらコードを記述し、誤変換が発生しないようにする必要があります。
しかし、Shift-JISにはUTF-8に変換できない文字が存在します。
例えば、いわゆる「半角カナ」は、Shift-JISには含まれているが、UTF-8には存在しないため、変換時に文字化けが発生することがあります。
さらに、特殊文字や拡張漢字も変換時に問題が発生する可能性があります。
特に、Windows固有の拡張文字セットや企業独自のカスタム文字が使用されている場合、変換ツールでは対応できないケースがあります。
以下の表は、Shift-JISとUTF-8の変換対応表の一例です。
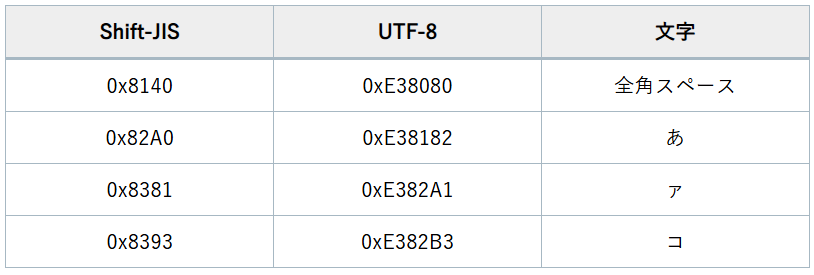
使えない文字の一覧としては、以下のようなものがあります。
- 半角カナ(Shift-JISに存在するが、UTF-8には存在しない)
- 特殊文字や拡張漢字(Shift-JISの一部文字はUTF-8に対応しない)
これらの文字に注意しながら変換を行うことで、文字化けを防ぐことができます。
特に、変換の際にはテスト環境で十分な確認を行い、本番環境でのエラーを防ぐことが重要です。
また、使用する変換ツールのバージョンや設定によっても結果が異なるため、最新のツールと正しい設定を使用することが推奨されます。

1.3. Shift-JISとUTF-8の文字化け原因と解消方法
Shift-JISとUTF-8の変換において文字化けが発生する主な原因はいくつかあります。
- 文字コードの誤解釈:
データの読み取り側が文字コードを正しく認識しない場合、文字化けが発生します。
例えば、Shift-JISでエンコードされたデータをUTF-8として読み取ると、正しい文字として表示されません。
これは、ウェブブラウザやテキストエディタがデータのエンコード方式を誤って解釈した場合に発生しやすい問題です。 - 未対応の文字:
先に述べたように、Shift-JISには存在するがUTF-8には存在しない文字がある場合、変換時に文字化けが発生します。
特に、企業独自のカスタム文字セットや古いアプリケーションで使用される拡張文字が含まれている場合に注意が必要です。 - 不完全な変換:
ファイルの一部が変換されずに残ると、文字化けが発生します。
例えば、大量のデータを一括変換する際に一部が欠けることがあります。
また、変換中にネットワークの障害やディスクのエラーが発生することで、データが完全に変換されないケースもあります。
これらの問題を解決するための方法はいくつかあります。
- 文字コードの統一:
データの保存、読み取り、表示のすべてで同じ文字コードを使用することで、文字化けを防ぎます。
例えば、すべてをUTF-8で統一することが有効です。
特に、ウェブサイトやデータベースでは、統一された文字コードの使用が推奨されます。 - 変換ツールの使用:
正確な文字コード変換を行うためのツールを使用することが推奨されます。
例えば、iconvやNKFなどのツールを使用すると、正確な変換が可能です。
これらのツールは、コマンドラインで簡単に使用でき、大量のデータを効率的に変換するためのオプションも豊富です。 - エンコーディングの明示:
データの送信や受信時に、使用する文字コードを明示することで誤解を防ぎます。
HTTPヘッダーやファイルのメタ情報にエンコーディングを記載することが効果的です。
例えば、ウェブページのHTMLヘッダーに「charset=utf-8」と明示することで、ブラウザが正しいエンコード方式を認識します。
さらに、定期的なデータのバックアップと監視も重要です。
データの変換中に予期せぬエラーが発生した場合でも、バックアップを利用することで迅速に復旧することができます。
また、エンコードの問題が発生した際には、速やかに対応できるように監視体制を整えることが重要です。
次に、具体的な変換ツールとしては、iconvやNKFの使用がおすすめです。
iconvは多くのオペレーティングシステムで利用可能で、コマンドラインから簡単に使用できます。
例えば、UTF-8からShift-JISに変換する場合は、以下のようなコマンドを使用します。
iconv -f UTF-8 -t Shift_JIS input.txt -o output.txtNKFは日本語の文字コード変換に特化したツールで、特にShift-JISとUTF-8の間の変換で高い精度を発揮します。
以下のコマンドを使用して、Shift-JISからUTF-8への変換を行います。
nkf -w input.txt > output.txt
これらの方法を活用して、Shift-JISとUTF-8の間での文字化けを防ぎましょう。
正しい文字コードの使用と管理が、データの正確性と一貫性を保つ鍵となります。
2. Unicode、UTF-8、Shift-JISの違いを理解して最適な選択を
Unicode、UTF-8、Shift-JISの違いを理解することは、特にウェブ開発やデータ処理を行う際に非常に重要です。
それぞれの文字コードには特有のメリットとデメリットがあり、適切な選択をすることで、作業の効率化やエラーの防止が期待できます。
この章では、それぞれのメリット・デメリット、具体的な利用シーン、そしてASCIIとUnicodeの対応表について詳しく解説します。
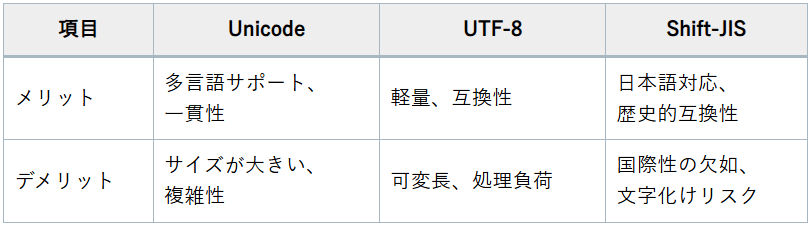
2.1. Unicode、UTF-8、Shift-JISのメリットとデメリット
まず、Unicode、UTF-8、Shift-JISのメリットとデメリットを見ていきましょう。
これらの情報は、どの文字コードがあなたのプロジェクトに最適かを判断する際に役立ちます。
Unicodeは、世界中のあらゆる文字を統一的に扱うことができるため、国際プロジェクトに非常に有用です。
そのメリットは次の通りです。
- 多言語サポート:
一つの文字コードで複数の言語をサポートできるため、グローバルなプロジェクトに最適。 - 一貫性: どのプラットフォームでも同じように表示されるため、互換性が高い。
デメリットとしては、以下の点が挙げられます。
- サイズが大きい:
全ての文字を網羅しているため、データサイズが大きくなりがち。 - 複雑性:
多くの文字を扱うため、エンコーディングやデコーディングが複雑になることがある。
UTF-8は、Unicodeの符号化方式の一つであり、以下のメリットがあります。
- 軽量:
英数字は1バイト、漢字は3バイトなど、文字に応じて効率的にデータを格納できる。 - 互換性:
ASCIIとの互換性が高く、既存のシステムと容易に統合できる。
デメリットとしては、
- 可変長:
可変長バイトを使用するため、特定の文字を扱う際に複雑さが増すことがある。 - 処理負荷:
一部の文字のエンコーディングやデコーディングにおいて、処理負荷がかかる場合がある。
Shift-JISは、日本語専用の文字コードであり、次のようなメリットがあります。
- 日本語対応:
日本語特有の文字を効率的に扱うことができる。 - 歴史的互換性:
古いアプリケーションや文書との互換性を保つことができる。
デメリットとしては、
- 国際性の欠如:
日本語以外の文字との互換性が低いため、国際プロジェクトには向かない。 - 文字化けリスク:
他の文字コードとの変換時に文字化けが発生しやすい。

2.2. Shift-JISとUTF-8、どっちがいいか?具体的な利用シーン
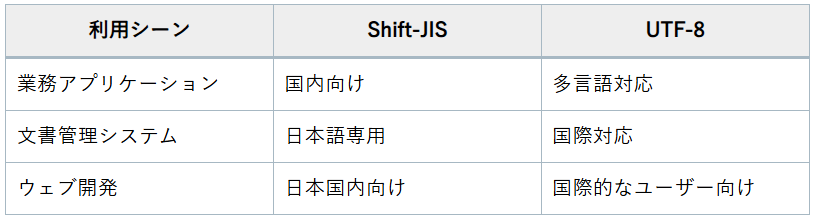
次に、Shift-JISとUTF-8のどちらを選ぶべきか、具体的な利用シーンを考慮してみましょう。
どちらの文字コードを選ぶかは、プロジェクトの内容や対象とするユーザーに大きく依存します。
Shift-JISは、日本国内での使用に特化しているため、以下のようなシーンで適しています。
- 国内専用アプリケーション:
日本国内のユーザーを対象とするアプリケーションやソフトウェアでは、Shift-JISが適しています。
特に、古いアプリケーションやシステムとの互換性が求められる場合に有効です。 - 既存システムの保守:
既存のシステムやデータベースがShift-JISを使用している場合、そのまま利用することで互換性を維持できます。
UTF-8は、国際的なプロジェクトや多言語対応が求められる場面で特に効果的です。
- ウェブ開発:
UTF-8はウェブページや電子メールで広く使用されており、特に国際的なユーザーを対象とするウェブサイトに最適です。
全世界の文字を統一的に扱うことができるため、言語の違いによる問題を避けることができます。 - データの交換:
異なるシステム間でのデータ交換において、UTF-8は高い互換性を持つため、データのやり取りがスムーズに行えます。
例えば、クラウドサービスやAPIを利用する際に、UTF-8を採用することで、データの互換性を保つことができます。
具体例として、以下のようなシーンが考えられます。
- Shift-JISの利用シーン
- 国内向けの業務アプリケーション
- 日本語を主に扱う文書管理システム
- 日本国内の顧客向けのソフトウェア
- 国内向けの業務アプリケーション
- UTF-8の利用シーン
- 多言語対応のウェブサイト
- 国際的な電子メール通信
- クラウドベースのデータストレージ
- 多言語対応のウェブサイト
これらの利用シーンを考慮して、プロジェクトのニーズに最適な文字コードを選択することが重要です。
2.3. ASCIIとUnicodeの対応表と変換ツールの紹介
最後に、ASCIIとUnicodeの対応表と変換ツールについて紹介します。
これらの情報は、特に異なる文字コード間でのデータのやり取りが発生する際に有用です。
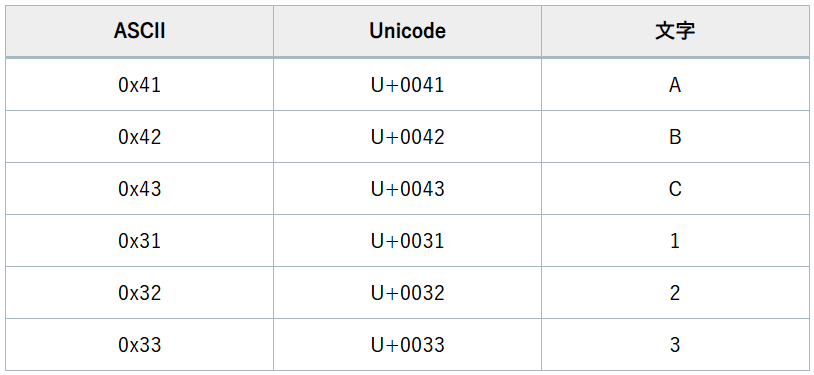
ASCIIは、英数字や基本的な記号を表現するための文字コードであり、0から127までの範囲で定義されています。
UTF-8は、ASCIIと互換性があるため、ASCII文字はそのままUTF-8として扱うことができます。
例えば、ASCIIの「A」(0x41)は、UTF-8でも同じ「0x41」としてエンコードされます。
Unicodeは、全世界の文字を統一的に扱うため、より広範な文字セットを持っています。
ASCII文字はUnicodeのサブセットであり、その対応表を使用することで、正確に変換が行えます。
以下は、ASCIIとUnicodeの簡単な対応表の例です。
変換ツールとしては、以下のものが広く利用されています。
- iconv:
さまざまな文字コード間での変換をサポートするコマンドラインツール。
多くのオペレーティングシステムで利用可能です。
例えば、LinuxやmacOS環境で次のように使用できます。
iconv -f UTF-8 -t ASCII input.txt -o output.txt- NKF (Network Kanji Filter):
日本語の文字コード変換に特化したツール。
特にShift-JISとUTF-8の間の変換で高い精度を発揮します。
以下のコマンドを使用して、Shift-JISからUTF-8への変換を行います。
nkf -w input.txt > output.txt- オンライン変換ツール:
ウェブブラウザから手軽に利用できる変換ツールも多数存在します。
例えば、ConvertioやEncode Explorerなどのオンラインツールを使用すると、迅速に変換が可能です。
これらのツールは、GUIを提供しており、プログラミング知識がなくても利用できます。
これらのツールを活用することで、正確な文字コードの変換が行えます。
特に、大量のデータを扱う際には、コマンドラインツールを使用することで効率的に作業を進めることができます。

これらの変換ツールを駆使して、異なる文字コード間でのデータのやり取りをスムーズに行いましょう。
正確な変換がデータの一貫性と信頼性を保つ鍵となります。

Unicode、UTF-8、Shift-JISの違いを徹底解説のまとめ
この記事では、Unicode、UTF-8、Shift-JISの違いについて詳しく解説しました。
それぞれの基本情報や変換対応表、メリットとデメリット、具体的な利用シーンなどを取り上げ、読者が自身のプロジェクトに最適な文字コードを選ぶための情報を提供しました。
- 基本情報と利用ケース:
- Unicode:
国際的な文字コード規格で、すべての文字を統一的に扱う。 - UTF-8:
Unicodeの符号化方式で、可変長バイトを使用し、ASCIIとの互換性が高い。 - Shift-JIS:
日本語用の文字コードで、日本国内のウェブサイトやアプリケーションで広く使用。
- Unicode:
- 変換対応表と使えない文字:
- 変換対応表:
Shift-JISとUTF-8の間でどのように変換されるかを示す。 - 使えない文字:
半角カナや特殊文字など、一部の文字は変換時に問題が発生。
- 変換対応表:
- メリットとデメリット:
- Unicode:
多言語サポート、一貫性。ただし、データサイズが大きくなる。 - UTF-8:
軽量で互換性が高いが、可変長バイトでの処理が複雑。 - Shift-JIS:
日本語対応が優れているが、国際性に欠ける。
- Unicode:
まとめとして、各文字コードの特性を理解し、自身のプロジェクトに最適な文字コードを選ぶことが重要です。
特に、国際的なプロジェクトではUnicodeやUTF-8を、日本国内向けのプロジェクトではShift-JISを選択するのが一般的です。
それぞれのメリットとデメリットをよく比較検討し、プロジェクトの成功に繋げてください。