Unicode、UTF-7、UTF-8の違いについて知りたい人は多くいるかもしれませんね。
この記事では、Unicodeの特長や形式、UTF-7とUTF-8の基本的な違い、さらにはUTF-16との比較、Unicode surrogateとUTF-8の関係について詳しく解説します。
また、UTF-7からUTF-8への変換方法や文字化けの修正方法、Unicodeの問題点とその対策、未来のネット接続におけるUnicodeの役割についても考察します。
この記事でわかること:
- Unicode、UTF-7、UTF-8の基本的な違いと特長
- UTF-7からUTF-8への変換方法と文字化けの修正方法
- Unicodeの問題点と対策、未来のネット接続での役割
これらの情報をもとに、最適なエンコーディングを選び、快適なネット生活を楽しみましょう。

本記事の内容
Unicode、UTF-7、UTF-8の違いを徹底解説
Unicode、UTF-7、UTF-8の違いについて知りたい方のために、このセクションではそれぞれの特長や形式について詳しく解説します。
基本的な概念から、それぞれのエンコーディング方式の違い、さらにはUnicode surrogateとの関係についても触れます。
これらの情報をもとに、最適なエンコーディング方式を選択し、より快適なネット環境を構築する手助けとなるでしょう。
- 特長と形式
- 基本的な違い
- UTF-16との比較
- surrogateとの関係
特長と形式
まず、Unicodeについて解説します。
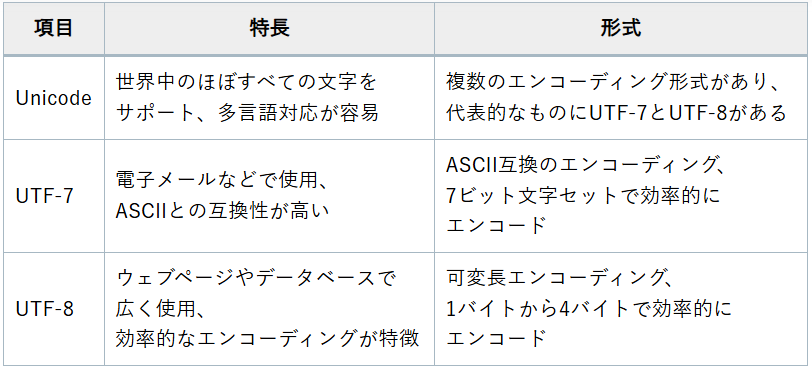
Unicodeは、世界中の文字を統一的に扱うための文字コード規格です。
これは、異なるプラットフォームや言語間で文字の正確な表示を可能にします。
特長:
- 広範な文字サポート:
世界中のほぼすべての文字をサポートしており、多言語対応が容易です。 - 互換性:
異なるシステム間での文字の互換性が保たれ、データのやり取りがスムーズに行えます。
形式:
- Unicodeには複数のエンコーディング形式があり、その中でも代表的なのがUTF-7とUTF-8です。
UTF-7は電子メールなどで使用されることが多く、ASCIIとの互換性が高いです。
一方、UTF-8はウェブページやデータベースで広く使用され、効率的なエンコーディングが特徴です。
例えば、Unicodeを使用することで、日本語や英語、アラビア語など、異なる言語の文字を同じデータベース内で混在させることが可能です。
これにより、国際的なビジネスやコミュニケーションがより円滑になります。
さらに、Unicodeはその普及により、プログラミングやデータ処理の現場で標準的な文字コードとして採用されています。
これにより、開発者は異なる言語やプラットフォーム間での文字の互換性を気にせずに作業が進められます。
基本的な違い
次に、UTF-7とUTF-8の基本的な違いについて解説します。
これらはどちらもUnicodeのエンコーディング形式ですが、その用途や特長には違いがあります。
UTF-7の特長:
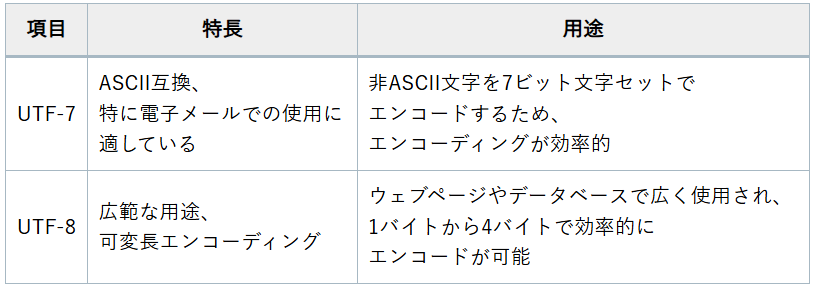
- ASCII互換:
UTF-7はASCIIと互換性があり、特に電子メールでの使用に適しています。 - エンコーディングの効率:
非ASCII文字をエンコードする際に、特定の7ビット文字セットを使用するため、エンコーディングが効率的です。
UTF-8の特長:
- 広範な用途:
UTF-8はウェブページやデータベースで広く使用されており、その汎用性が高いです。 - 効率的なエンコーディング:
1バイトから4バイトの可変長エンコーディングを使用し、文字のエンコード効率が高いです。
例えば、ウェブサイトを多言語対応する場合、UTF-8を使用することで、異なる言語の文字を効率的にエンコードすることができます。

一方、電子メールの本文をエンコードする場合には、ASCIIとの互換性が求められるため、UTF-7が適しています。
また、UTF-7とUTF-8の違いを理解することで、適切なエンコーディング方式を選択し、通信の効率化やデータの正確な伝達が可能となります。
例えば、UTF-8を選択することで、大量のデータを効率的に処理することができます。
UTF-16との比較
次に、UTF-7、UTF-8、UTF-16の違いとその比較について解説します。
これらのエンコーディング形式には、それぞれ異なる特長と用途があります。
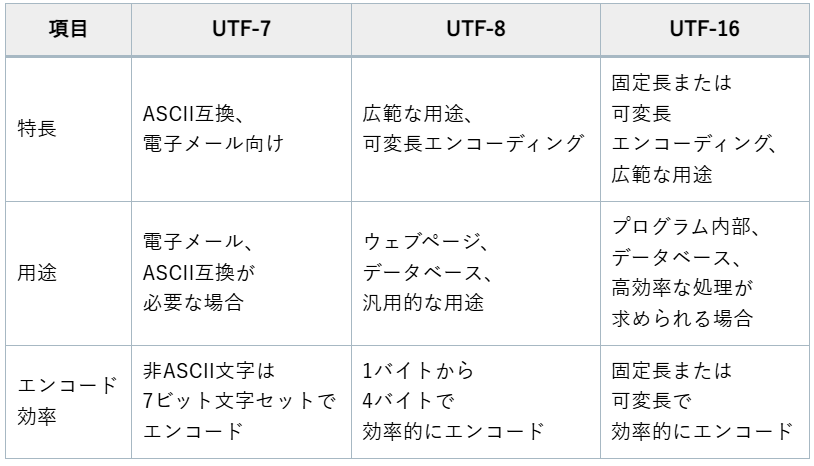
例えば、電子メールのエンコードにはASCIIとの互換性が必要なため、UTF-7が適しています。
一方、ウェブページやデータベースでのエンコードには、広範な用途に対応できるUTF-8が最適です。
プログラム内部や高効率なデータ処理が求められる場合には、固定長または可変長エンコーディングを持つUTF-16が適しています。
これにより、適切なエンコーディング方式を選択し、効率的なデータ処理と正確な文字表示が可能となります。
surrogateとの関係
最後に、Unicode surrogateとUTF-8の関係について解説します。
Unicode surrogateとは、サロゲートペアとして知られるもので、高位サロゲートと低位サロゲートの組み合わせで1つの文字を表現します。
Unicode surrogateの特長:
- 拡張文字の対応:
Unicodeの範囲外の文字(通常の文字セットに含まれない文字)を表現するために使用されます。 - 16ビットのサロゲートペア:
16ビットの高位サロゲートと低位サロゲートを組み合わせることで、1つの文字を表現します。
UTF-8との関係:
- エンコード方法:
UTF-8では、サロゲートペアを含む文字を1バイトから4バイトの可変長エンコーディングで表現します。 - 互換性:
UTF-8は、サロゲートペアを正確にエンコードおよびデコードするため、Unicodeのすべての文字を正確に表現できます。
例えば、絵文字や特殊文字など、通常の文字セットに含まれない文字を使用する場合、Unicode surrogateとUTF-8を使用することで、これらの文字を正確に表現することができます。
また、UTF-8の可変長エンコーディングにより、文字のエンコード効率が向上し、データ量の削減が可能となります。
これにより、通信速度の向上やストレージの効率化が図れます。
さらに、Unicode surrogateとUTF-8の組み合わせは、多言語対応が求められる現代のウェブやアプリケーションで非常に重要です。
多様な文字を正確に表示するためには、この組み合わせが欠かせません。

これらの情報を理解することで、Unicode、UTF-7、UTF-8の違いや特長を把握し、最適なエンコーディング方式を選択して、より快適なネット環境を構築することができます。

Unicode、UTF-7、UTF-8の違いを理解して効率的に使う方法
Unicode、UTF-7、UTF-8の違いを理解することで、効率的にエンコーディングを使いこなすことができます。
このセクションでは、具体的な変換方法や文字化けの修正方法、Unicodeの問題点とその対策、さらに未来のネット接続におけるUnicodeの役割について詳しく説明します。
- 変換方法
- 文字化けとその修正方法
- 問題点とその対策
- 未来のネット接続と役割
変換方法
まず、UTF-7からUTF-8への変換方法について説明します。
UTF-7は電子メールなどで使用されることが多いですが、現代のウェブやアプリケーションではUTF-8が主流です。
そのため、UTF-7をUTF-8に変換する方法を知っておくことは重要です。
変換手順:
- 文字コードを読み取る:
まず、UTF-7でエンコードされたデータを読み取ります。 - デコード:
UTF-7からUnicodeにデコードします。
これにより、内部でUnicode形式に変換されます。 - 再エンコード:
デコードしたUnicodeデータをUTF-8形式に再エンコードします。
例えば、Pythonなどのプログラミング言語を使用する場合、以下のようなコードで変換できます。
# UTF-7からUTF-8への変換例
data_utf7 = b'+AEY-'
data_unicode = data_utf7.decode('utf-7')
data_utf8 = data_unicode.encode('utf-8')
print(data_utf8)これにより、UTF-7でエンコードされたデータをUTF-8形式に変換することができます。
また、テキストエディタやオンライン変換ツールを使用することでも簡単に変換が可能です。
例えば、Notepad++やオンラインのエンコード変換ツールを利用して、UTF-7からUTF-8への変換を行うことができます。
文字化けとその修正方法
次に、UTF-7の文字化けとその修正方法について解説します。
文字化けは、異なるエンコーディング形式間でデータが正しく解釈されない場合に発生します。
文字化けの原因:
- 不正なデコード:
UTF-7でエンコードされたデータを、他のエンコーディング形式としてデコードする場合。 - 不完全なデータ:
データが途中で途切れている場合や、正しくエンコードされていない場合。
修正方法:
- 正しいエンコーディング形式を使用する:
まず、データが正しいエンコーディング形式でデコードされているか確認します。 - 完全なデータを確認する:
データが途中で途切れていないか、完全に受信されているか確認します。 - 再エンコード:
データを再エンコードし、正しい形式で保存します。
例えば、Pythonを使用して文字化けを修正する場合、以下のようにデータを正しくデコードし、再エンコードすることができます。
# UTF-7の文字化け修正例
data_utf7 = b'+AEY-'
try:
data_unicode = data_utf7.decode('utf-7')
data_utf8 = data_unicode.encode('utf-8')
print(data_utf8)
except UnicodeDecodeError:
print("デコードエラーが発生しました。")これにより、UTF-7の文字化けを修正し、正しい形式でデータをエンコードできます。
また、テキストエディタやエンコード変換ツールを使用することで、簡単に文字化けを修正することも可能です。
問題点とその対策
次に、Unicodeの問題点とその対策について説明します。
Unicodeは多言語対応に優れた文字コード規格ですが、いくつかの問題点もあります。
問題点:
- データ量の増加:
Unicodeの文字は多くの場合、1文字あたり複数バイトを使用するため、データ量が増加します。 - 互換性の問題:
古いシステムやアプリケーションがUnicodeに対応していない場合があります。 - サロゲートペアの扱い:
一部の文字はサロゲートペアとして表現されるため、処理が複雑になることがあります。
対策:
- 適切なエンコーディングを選択する:
データの用途や環境に応じて、最適なエンコーディング形式を選択します。 - 互換性の確認:
古いシステムやアプリケーションがUnicodeに対応しているか確認し、必要に応じてアップデートを行います。 - サロゲートペアの処理:
プログラムやデータベースでサロゲートペアを正しく処理するためのロジックを実装します。
例えば、ウェブアプリケーションを開発する場合、UTF-8を選択することで、多言語対応が容易になります。
また、システムのアップデートを行い、最新のUnicodeバージョンに対応することが重要です。
未来のネット接続と役割
最後に、未来のネット接続とUnicodeの役割について考察します。
Unicodeは、多言語対応や異なるシステム間での互換性を確保するために不可欠な技術です。
未来のネット接続における役割:
- 多言語対応:
インターネットがますますグローバル化する中で、多言語対応はますます重要になります。
Unicodeは、異なる言語間でのコミュニケーションを円滑にするための基盤となります。
例えば、オンラインプラットフォームやソーシャルメディアでは、異なる言語を使用するユーザー同士がやり取りする機会が増えており、Unicodeを使用することで文字化けや誤解を防ぎ、スムーズなコミュニケーションが可能になります。
IoTとUnicode:
IoT(Internet of Things)の普及により、異なるデバイス間でのデータ通信が増加します。
Unicodeを使用することで、異なるデバイス間でのデータの互換性を確保できます。
例えば、スマートホームデバイスやウェアラブルデバイスが増える中で、Unicodeはそれらのデバイス間のデータ交換を円滑にし、ユーザーエクスペリエンスを向上させます。
セキュリティ:
Unicodeはセキュリティの面でも重要です。
例えば、異なるエンコーディング方式を使用することで、データの改ざんや不正アクセスを防ぐことができます。
特に、機密情報を扱う企業や政府機関では、Unicodeを用いることでデータの一貫性とセキュリティを保つことが求められます。
さらに、未来のネット接続においても、Unicodeはその役割を果たし続けるでしょう。
新しい技術やサービスが登場するたびに、Unicodeがそれらの基盤として機能し、多言語対応やセキュリティの向上を支えることになります。
これにより、ユーザーはより安全で便利なインターネット環境を享受できるでしょう。
このように、未来のネット接続においてもUnicodeは重要な役割を果たし続けます。

Unicode、UTF-7、UTF-8の違いをわかりやすく徹底解説!のまとめ
この記事では、Unicode、UTF-7、UTF-8の違いについて詳しく解説しました。
これらのエンコーディングの特長と用途を理解することで、最適な使用方法を見つける手助けとなるでしょう。
Unicodeの特長と形式:
- 世界中のほぼすべての文字をサポート。
- 複数のエンコーディング形式が存在し、UTF-7とUTF-8が代表的。
UTF-7とUTF-8の違い:
- UTF-7はASCII互換で、特に電子メール向け。
- UTF-8は広範な用途に対応し、効率的な可変長エンコーディング。
UTF-7、UTF-8、UTF-16の比較:
- UTF-7は電子メールやASCII互換が必要な場合に最適。
- UTF-8はウェブページやデータベースでの使用に適し、可変長エンコーディング。
- UTF-16はプログラム内部やデータベースでの高効率な処理に対応。
Unicode surrogateとUTF-8の関係:
- 拡張文字を表現するためにサロゲートペアを使用。
- UTF-8はサロゲートペアを正確にエンコードし、多言語対応を円滑にする。
UTF-7からUTF-8への変換方法:
- 文字コードを読み取り、デコードして再エンコードする。
UTF-7の文字化けと修正方法:
- 正しいエンコーディング形式を使用し、完全なデータを確認して再エンコード。
Unicodeの問題点と対策:
- データ量の増加や互換性の問題、サロゲートペアの扱いに注意。
- 適切なエンコーディングを選び、互換性を確認し、正しい処理を実装する。
未来のネット接続とUnicodeの役割:
- 多言語対応やIoTのデータ互換性、セキュリティの向上に貢献。
これらのポイントを理解することで、Unicode、UTF-7、UTF-8の違いを把握し、効率的に活用できます。
最適なエンコーディング方式を選び、快適なネット環境を構築しましょう。