Linuxのシェルスクリプトを触っていると、「&&」の使い方に戸惑ったことはありませんか?
この記事では、Linuxでの「&&」の基本的な使い方から、他の演算子や特殊文字との違いについて詳しく解説します。
さらに、具体的な使用例やシェルスクリプトでの応用方法についても触れています。
この記事でわかること:
- Linuxの「&&」と「if」の違いと使い方
- パイプとの違い
- 「&」と「&&」の違い
- 「2>&1」と「>&」の違い
- 「||」と「&&」の違い
- セミコロンとの違い
これらのポイントを押さえて、Linuxコマンドをより効率的に使いこなせるようになりましょう。

本記事の内容
Linuxの&&の使い方と他の演算子との違い
Linuxのシェルスクリプトでよく使われる「&&」ですが、具体的な使い方や他の演算子との違いを理解していない方も多いかもしれません。
この記事では、Linuxでの「&&」の使い方を詳しく解説し、他の演算子との違いについても説明します。
それぞれの特徴を理解し、適切に使い分けることで、より効率的なシェルスクリプトを書く手助けとなるでしょう。
- ifとの違いと使い方
- パイプと&&
- コマンドでの&と&&
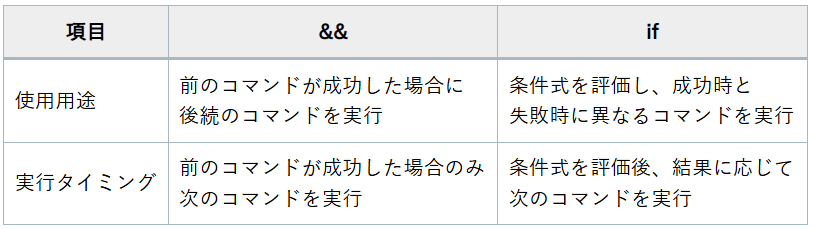
ifとの違いと使い方
まずは、「&&」と「if」の違いについて見てみましょう。
「&&」と「if」はどちらも条件付きでコマンドを実行するために使われますが、使い方や挙動には違いがあります。
「&&」の基本的な使い方:
「&&」は、前のコマンドが成功した場合にのみ、後続のコマンドを実行します。
例えば、command1 && command2と書くと、command1が成功した場合にのみcommand2が実行されます。
これにより、エラーが発生した場合の次の処理を防ぐことができます。
「if」の基本的な使い方:
一方、「if」は条件式を評価し、その結果に基づいて異なるコマンドを実行します。例えば、
if command1; then
command2
else
command3
fiというように、command1が成功した場合はcommand2が実行され、失敗した場合はcommand3が実行されます。
これにより、エラーが発生した場合の対処を柔軟に行うことができます。
具体例として、ディレクトリの存在を確認し、その後にファイルをコピーする場合を考えてみましょう。
「&&」を使用する場合:
[ -d /path/to/dir ] && cp /path/to/source /path/to/dirこのコマンドは、ディレクトリが存在する場合にのみファイルをコピーします。
存在しない場合、コピーは行われません。
「if」を使用する場合:
if [ -d /path/to/dir ]; then
cp /path/to/source /path/to/dir
else
echo "Directory does not exist."
fiこのコマンドは、ディレクトリが存在する場合にファイルをコピーし、存在しない場合はエラーメッセージを表示します。
これにより、ユーザーに対して明確なフィードバックを提供できます。
このように、簡単な条件付き実行には「&&」が便利ですが、複雑な条件分岐やエラーハンドリングが必要な場合には「if」を使うと良いでしょう。
使い分けることで、スクリプトの可読性とメンテナンス性が向上します。
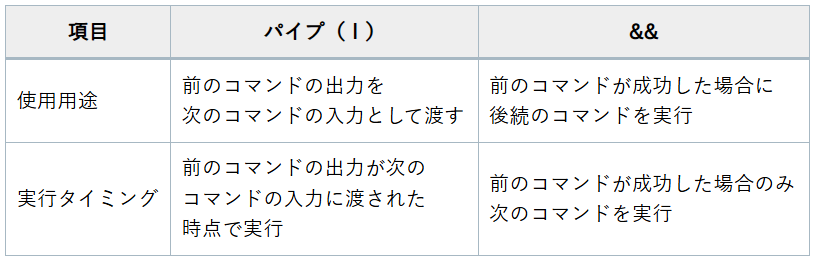
パイプと&&
次に、「パイプ(|)」と「&&」の違いについて見てみましょう。
どちらも複数のコマンドを連結して実行するために使われますが、その役割は異なります。
パイプの基本的な使い方:
パイプ「|」は、前のコマンドの出力を次のコマンドの入力として渡します。
例えば、command1 | command2と書くと、command1の出力がcommand2の入力として渡されます。
これにより、複数のコマンドを組み合わせて複雑な処理を行うことができます。
具体例として、ファイルの内容を検索する場合を考えてみましょう。
cat file.txt | grep "search_string"このコマンドは、file.txtの内容を表示し、その中からsearch_stringを含む行を抽出します。
これにより、大量のデータから特定の情報を迅速に見つけることができます。
「&&」の基本的な使い方:
一方、「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行します。
これにより、エラーが発生した場合の次の処理を防ぎ、スクリプトの信頼性を向上させます。
具体例として、ディレクトリを作成し、その後にファイルを作成する場合を考えてみましょう。
mkdir /path/to/dir && touch /path/to/dir/newfile.txtこのコマンドは、ディレクトリの作成に成功した場合にのみファイルを作成します。
これにより、ディレクトリが存在しない場合にファイルが作成されることを防ぎます。
パイプと&&の違いを理解することで、適切なツールを選んで効率的なスクリプトを作成することができます。
パイプはコマンドの出力を次のコマンドに渡す役割を持ち、前のコマンドの成功や失敗に関係なく実行されるのに対し、&&は前のコマンドが成功した場合にのみ次のコマンドを実行します。
したがって、出力の連結が必要な場合にはパイプを使い、条件付きで次のコマンドを実行する場合には「&&」を使うと良いでしょう。

コマンドでの&と&&
最後に、「&」と「&&」の違いについて見てみましょう。
これらは見た目が似ていますが、使い方や挙動には大きな違いがあります。
「&」の基本的な使い方:
「&」は、コマンドをバックグラウンドで実行するために使われます。
例えば、command &と書くと、commandがバックグラウンドで実行され、シェルはすぐに次のプロンプトを返します。
これにより、ユーザーは他の作業を続けることができます。
具体例として、長時間かかる処理をバックグラウンドで実行する場合を考えてみましょう。
sleep 60 & # 60秒間待機するコマンドをバックグラウンドで実行
このコマンドは、バックグラウンドで60秒間の待機を開始し、すぐに次のプロンプトが表示されます。
これにより、ユーザーは待機中に他の作業を行うことができます。
「&&」の基本的な使い方:
一方、「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行します。
これにより、エラーが発生した場合の次の処理を防ぎ、スクリプトの信頼性を向上させます。
具体例として、ファイルをコピーし、その成功を確認する場合を考えてみましょう。
cp source_file destination_file && echo "Copy successful"このコマンドは、ファイルのコピーが成功した場合にのみ「Copy successful」を表示します。
これにより、ユーザーはコピーが成功したかどうかを簡単に確認できます。
このように、「&」はコマンドをバックグラウンドで実行し、「&&」は前のコマンドが成功した場合にのみ次のコマンドを実行します。
それぞれの特性を理解し、適切に使い分けることが重要です。

Linuxの&&と他の特殊文字や演算子との違い
Linuxでは多くの特殊文字や演算子が使われます。
特に「&&」はよく使われる演算子の一つですが、他の特殊文字や演算子との違いを理解することで、より効率的にコマンドを使いこなすことができます。
このセクションでは、Linuxコマンドにおける「2>&1」と「>&」、「||」と「&&」、「セミコロン」と「&&」の違いについて詳しく解説します。
それぞれの使い方と違いを理解し、適切に使い分けることで、スクリプト作成のスキルを向上させましょう。
- 「2>&1」と「>&」
- ||と&&
- セミコロンと&&
「2>&1」と「>&」
まず、「2>&1」と「>&」の違いについて見ていきましょう。
これらはリダイレクトに使われる特殊文字で、それぞれの役割を理解することが重要です。
「2>&1」の基本的な使い方:
- 「2>&1」は、標準エラー出力(stderr)を標準出力(stdout)にリダイレクトするために使われます。
例えば、command 2>&1と書くと、コマンドのエラー出力が標準出力に統合されます。
これにより、出力を一つのストリームにまとめることができます。
「>&」の基本的な使い方:
- 一方、「>&」は、Bash 4以降のバージョンで使用される簡略化されたリダイレクト記法です。
「>&1」は「2>&1」と同じ意味を持ちます。
例えば、command >&1と書くと、同様に標準エラー出力が標準出力にリダイレクトされます。
具体例として、コマンドの出力とエラーを一つのファイルにまとめる場合を考えてみましょう。
「2>&1」を使用する場合:
command > output.txt 2>&1このコマンドは、標準出力と標準エラー出力を両方ともoutput.txtファイルにリダイレクトします。
「>&」を使用する場合:
command > output.txt >&1このコマンドも、同様に標準出力と標準エラー出力をoutput.txtファイルにリダイレクトします。
このように、「2>&1」と「>&」は同じ目的を持ちますが、記法が異なるだけです。
Bashのバージョンによっては「>&」が使えない場合もあるので、注意が必要です。


||と&&
次に、「||」と「&&」の違いについて見てみましょう。
どちらも条件付きでコマンドを実行するために使われますが、条件の評価方法が異なります。
「||」の基本的な使い方:
- 「||」は、前のコマンドが失敗した場合に後続のコマンドを実行します。
例えば、command1 || command2と書くと、command1が失敗した場合にのみcommand2が実行されます。
「&&」の基本的な使い方:
- 一方、「&&」は、前のコマンドが成功した場合にのみ後続のコマンドを実行します。
例えば、command1 && command2と書くと、command1が成功した場合にのみcommand2が実行されます。
具体例として、ディレクトリの存在を確認し、存在しない場合に作成する場合を考えてみましょう。
「||」を使用する場合:
[ -d /path/to/dir ] || mkdir /path/to/dirこのコマンドは、ディレクトリが存在しない場合にのみディレクトリを作成します。
「&&」を使用する場合:
[ -d /path/to/dir ] && echo "Directory exists"このコマンドは、ディレクトリが存在する場合にのみメッセージを表示します。
「||」と「&&」の違いを理解することで、エラーハンドリングや条件付き実行を効果的に行うことができます。
それぞれの用途に応じて適切に使い分けましょう。
セミコロンと&&
最後に、セミコロン(;)と「&&」の違いについて見てみましょう。
どちらも複数のコマンドを連結して実行するために使われますが、実行順序に違いがあります。
セミコロン(;)の基本的な使い方:
- セミコロン(;)は、前のコマンドの成否に関係なく、すべてのコマンドを順次実行します。
例えば、command1; command2と書くと、command1が成功しても失敗してもcommand2が実行されます。
「&&」の基本的な使い方:
- 一方、「&&」は、前のコマンドが成功した場合にのみ後続のコマンドを実行します。
例えば、command1 && command2と書くと、command1が成功した場合にのみcommand2が実行されます。
具体例として、ファイルをコピーし、その後の処理を行う場合を考えてみましょう。
セミコロン(;)を使用する場合:
cp source_file destination_file; echo "Copy attempted"このコマンドは、ファイルのコピーが成功しても失敗しても「Copy attempted」が表示されます。
「&&」を使用する場合:
cp source_file destination_file && echo "Copy successful"このコマンドは、ファイルのコピーが成功した場合にのみ「Copy successful」が表示されます。
セミコロンと「&&」の違いを理解することで、スクリプトの実行順序をより柔軟に制御できます。状況に応じて適切に使い分けることが重要です。


Linuxの&&の使い方とは?他の演算子との違いを徹底解説します!のまとめ
この記事では、Linuxでの「&&」の使い方と他の演算子との違いについて詳しく解説しました。
各演算子の基本的な使い方から具体例まで、実際の使用シーンをイメージしやすい形でご紹介しました。
以下に要点をまとめます。
- &&とifの違いと使い方:
- 「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行。
- 「if」は条件式を評価し、成功時と失敗時に異なるコマンドを実行。
- 「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行。
- パイプ(|)と&&の違い:
- パイプは前のコマンドの出力を次のコマンドの入力として渡す。
- 「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行。
- パイプは前のコマンドの出力を次のコマンドの入力として渡す。
- &と&&の違い:
- 「&」はコマンドをバックグラウンドで実行。
- 「&&」は前のコマンドが成功した場合にのみ次のコマンドを実行。
- 「&」はコマンドをバックグラウンドで実行。
- 2>&1と>&の違い:
- 「2>&1」は標準エラー出力を標準出力にリダイレクト。
- 「>&」も同様にリダイレクトを行うが、Bash 4以降の簡略記法。
- 「2>&1」は標準エラー出力を標準出力にリダイレクト。
- ||と&&の違い:
- 「||」は前のコマンドが失敗した場合に後続のコマンドを実行。
- 「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行。
- 「||」は前のコマンドが失敗した場合に後続のコマンドを実行。
- セミコロン(;)と&&の違い:
- セミコロンは前のコマンドの成否に関係なく後続のコマンドを実行。
- 「&&」は前のコマンドが成功した場合にのみ後続のコマンドを実行。
- セミコロンは前のコマンドの成否に関係なく後続のコマンドを実行。
これらのポイントを理解することで、Linuxコマンドをより効率的に使いこなすことができます。
適切な演算子を使い分け、スクリプトの可読性と信頼性を向上させましょう。